
10 practical tips for reproducible Machine Learning
The one where you get some advice to make your workflows more reproducible
The boom of Machine Learning and AI solutions is undeniable. We have “AI” enabled everything: from medical diagnosis optimisation to HR and beer brewing processes. But thanks to this boom, we have also realised that developing and productising such products is hard, really hard. And it was not long before we started seeing these kinds of articles popping, well, everywhere:


What is reproducibility, and why do we care?
A result is reproducible when the same analysis steps performed on the same dataset consistently produces the same answer. Reproducible Machine Learning can avoid significant errors and costs in the future. As well as making it easier to track and explain the insights/predictions generated.
But beyond that, working reproducibly facilitates collaboration and review processes, ensures continuity of your work and retains institutional knowledge and future proofs your work. This is extremely important because most of the time, we do not work alone but with a group of data scientists, software engineers and many other stakeholders.
The truth is that reproducibility in Machine Learning is a problem that every practitioner faces daily.
Have you ever found yourself wondering any of the following?:
- What version of the dataset was used to train this algorithm?
- What version of the algorithm/model do we have in R&D/staging/production/was published in the paper?
- Did we keep track of all the parameters and features we explored and the baseline models?

We have all been there, trust me.
So without further ado, let’s dive into how to make your workflows more reproducible.
0. Identifying the key players
The base for reproducible workflows lies in being able to track and reproduce your data, computational environment and code. So you will notice that most of the recommendations here centre around these three critical assets:

I am not going to dive too much into this (as this deserves a whole post for itself). But, you ideally want to make all your work reproducibility across three levels:
- Methodology: for example, how your formulate your experiments and prove or disprove your hypothesis.
- Model/algorithm (though Machine Learning goes way beyond models that get deployed). For example, explain the complexity of your algorithm and the space you are covering how were your hyperparameters chosen.
- Infrastructure: here you want to ensure that there are a robust infrastructure folk others to access your data and run your code. Make sure also to describe the hardware you used (i.e. GPU).

1. Always know what you are expecting from your data.
We all know how vital good quality data is for good quality and reliable Machine Learning. So we always should know what we are expecting from our data at all times - what types, distributions, ranges and schemas.
One of my favourite tools to do this is Great expectations as it integrates with other tools I use like Spark, Airflow, Jupyter Notebooks and pandas (among others). It is an excellent tool for data validation, testing and documentation.
For example, if you have a raw data source on which you do some manipulation before storing it in a database, you can add multiple validation steps for your input and output data.

If you are collecting data from third-party APIs, you can use JSON schema to validate against the meta schema.
2. Develop pipelines.
The best way to keep track of all your outputs, inputs, metrics, models and data even before using specialised tools is being able to keep track of each task you are performing.
Many tools allow you to build robust pipelines. Many of which revolve around the concept of Directed acyclic graphs. Some of my favourites are:
- Dagster: I have found that it is super easy to use and has native Jupyter integration (win!).
- Airflow: this Apache incubator project has gained loads of popularity. The UI makes it very easy to have an overview of your DAGs and their statuses.
These add a lot more complexity:
However, you decide to implement your pipelines keep this rule of thumb in mind:
✨ Top tip: Split your tasks into atomic units of work. Where each node of your DAG or each step in your pipeline does one single task.
This helps avoid the “Change anything Change everything” (Scully et all) problem.
3. ML loves randomness - deal with it.
There is randomness everywhere:
- Random initialisations
- Random augmentations
- Random noise introductions
- Data shuffles
The sound advice that you will find everywhere is always set and save your seed.
If working with Python, you should often find yourself performing a version of this ritual:
import os
import tensorflow
import numpy
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
tensorflow.random.set_seed(seed)
numpy.random.seed(seed)
tensorflow.keras.layers.Dropout(x, seed=SEED)
tensorflow.image.random_flip_left_right(x, seed=seed)
tensorflow.random_normal_initializer(x, y, seed=seed)
Another source of randomness is - data! When we split the data for training and validation, we often use different splits.
The solution: fix train and validation splits before training - if using methods like test_split_train from scikit-learn make sure also to specify the seed argument.
4. Hyperparameters everywhere
Finding the right hyperparameters for your models can be quite an involved process. These can be particularly problematic when you are running multiple experiments with different network architectures.
✨ Top tip: As a rule of thumb: not only keep track of the parameters but also of the output metrics of each model associated and your selection process/baseline.
An excellent example of how to keep track of your hyperparameters in a sane manner can be found in the Pachyderm distributed hyperparameter tuning sample.
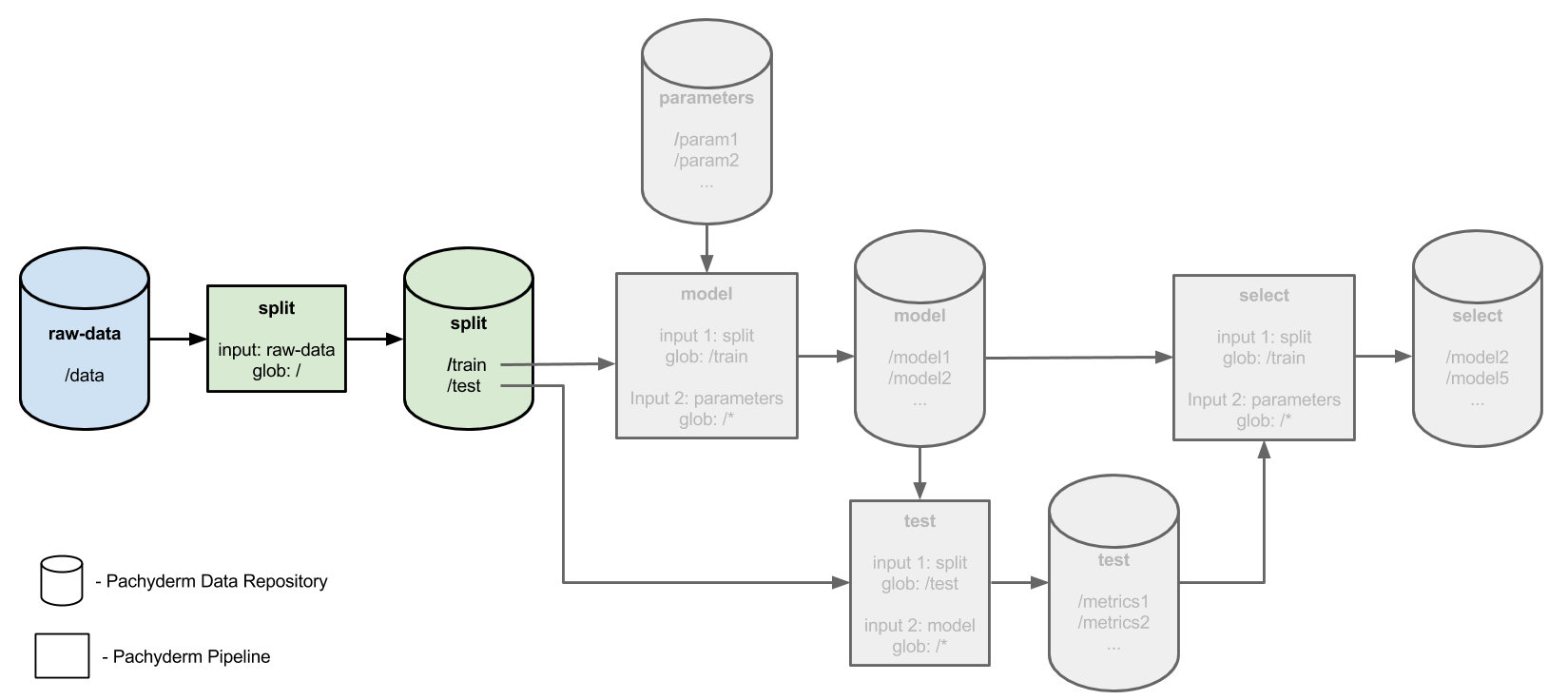 .
.
The use of pipelines to split, train, test, and select the models and hyperparameter makes it so much easier to keep track of the outputs at all stages as well as reporting on the rationale behind why you chose specific hyperparameters.
5. & 6. Version control & data decoupling.
How often have you worked on pieces of code that had lines like this:
import pandas as pd
df = pd.read_csv("../../../data.csv")
In this scenario, both data and code are tightly coupled. To ensure reproducibility, you want to keep track of both your code and your data versions. Not only for the final outputs but also the intermediate results.
Imagine you have a workflow like this:

Although this is a somewhat simplified pipeline, there are still multiple outputs which you want to track (data, code and serialised files).
A great tool for this is dvc - which allows you to keep track of all your assets with Git without * storing your data in Git*. This allows you to decouple data and code and their respective versions to ensure reproducibility:
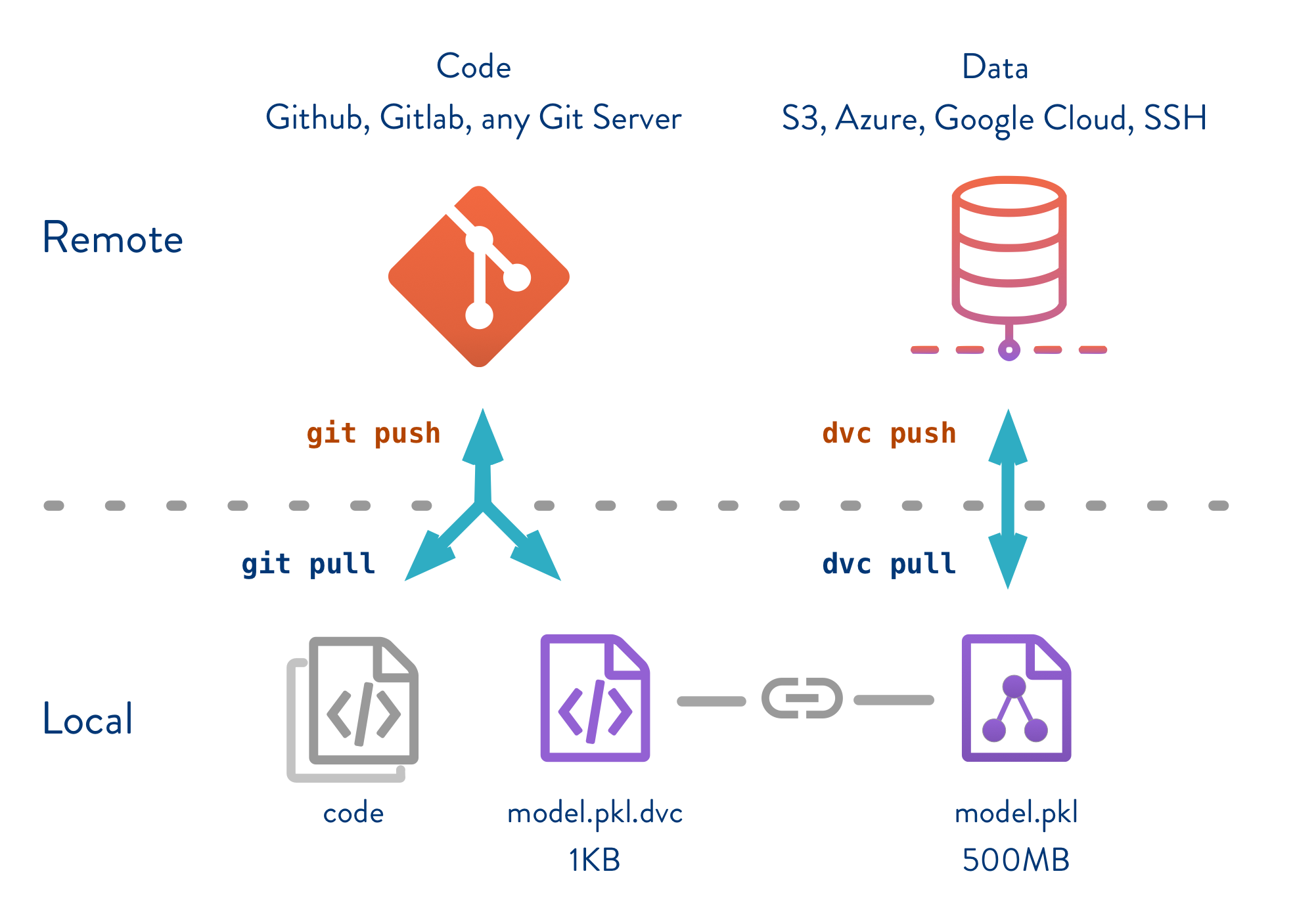
7. Testing
Testing in Machine Learning can be quite complex. Again, I am not going to dive too much into this as testing strategies deserve a post for itself. So here is a checklist of testing strategies and items you need to consider testing:
- API calls and contract tests against your data schemas
- Integration tests for your pipelines
- Regression tests
- Unit tests - test your methods, transformations
- Test that model weights and outputs are numerically stable
- Reproducibility across environments: development, staging and production. The predictions across these should be the same.
✨ Top tip: A package I find using over and over again is Hypothesis for property-based testing. It not only has simplified my testing strategies but also has increased my confidence in the tests.
There are extensions to Hypothesis which are worth checking: https://hypothesis.readthedocs.io/en/latest/strategies.html.
8. Reproducible environments
For a piece of work to be reproducible, the computational environment that it was conducted in must be captured so that others can replicate it.
Many tools allow you to create reproducible environments or at least to get close to.
Depending on the projects I am working on, I tend to mix some of these tools:
And I am still a fan of Make because it is fantastic.
✨ Top tips:
- There is no one size fits all. Choose the most appropriate method for your project for capturing your computational environment
- Capture your computational environment - I recommend not only pinning the main dependencies but also the sub dependencies and use a tool with dependency resolutions (pip-tools, pipenv and Poetry are proper tools to do this)
- Share your captured computational environment along with your code and data if possible
9. Automate
A lot of errors can be introduced when we depend too much on the human-in-the loop for our workflows. So whenever possible automate stuff not only, it will save you time but will optimise your workflows and increase your confidence.
Some great tools I use for automation are:
- Tox - for automated testing
- Nox - flexible test automation
- Invoke - general-purpose task execution (quite similar to Make but Python-specific)
- Repo2docker - create Docker containers from GitHub repositories
- Binder - create reproducible interactive environments from GitHub repositories
- GitHub actions - Continuous integration and devliery as well as workflow automation
✨ Top tip: Start automating the most critical parts - deployment, container creation, testing and move from there.
10. Consistency and standards
With the myriad of tools and workflows out there there is not a single solution for the reproducibility problem.
But what I have found is that consistency is critical. Here are my last ✨ Top tips:
- Have a consistent project structure. You can use tools like data science cookiecutter.
- Adhere to coding standards:
- Document and documentation as code.
- Many folks do not enjoy writing documentation. But something I started doing a while ago is treating docs as code (well almost). I build all my docs through my continuous integration pipelines, and I also run tests on them.
- Choosing tools:
- I have mentioned many tools here. But each of them come with a learning curve and tricks you have to learn. Chose what works for you and learn it well, rather than trying to learn how to use all the tools.
That is it! These are some practical tips to get you started with Reproducible Machine Learning.

